引言
APM,Application Performance Managment的缩写,即:“应用性能管理”。现代的APM体系,基本都是参考Google的《Dapper,大规模分布式系统的跟踪系统》的体系来实践的。
随着中台、微服务、云原生架构的流行,应用系统本身正变得越来越难以管理,终端用户的一次请求往往需要涉及到多个服务,因此服务性能监控和问题排查就变得异常的复杂。不同的服务可能由不同国家,不同团队,和不同编程语言来实现。服务可能部署在成千上万台服务器,跨越不同机房,不同数据中心。
此时需要一个可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,这就是APM系统。
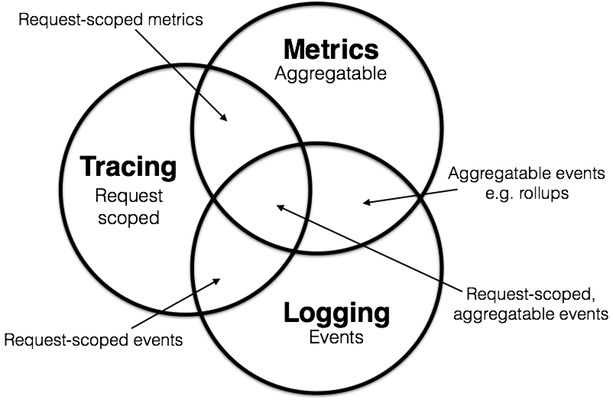
Metrics、Tracing和Logging是APM中三个主要的概念,Metrics、Tracing和Logging是有交叠的地方。从左边线条的箭头方向看成本会越来越高。Metrics、Tracing和Logging三者之间的成本关系(以存储成本计算):
-
Metrics 更节省存储资源,因为数据会被聚合后存储。
-
Logging 需要的存储空间最大,成本最高。
-
Tracing 也是存储大户,由于它的业务特点可以采样,所以总体存储成本则介于两者之间。
市面上产品:
- Apache Skywalking
- ELK stack
- prometheus
- open-falcon
- Sensu
- pinpoint
- zipkin