整理 java.util.concurrent 并发框架内的常用类库,包括并发容器(Map、Queue、List 等)、原子操作类、并发工具类、线程池等。
并发 map
HashTable
使用 synchronized 来保证线程安全,key 和 value 均不可以为 null,put 和 get 方法均用 synchronized 修饰。
SynchronizedMap
Collections.synchronizedMap() 使用 synchronized 来保证线程安全,根据初始化参数类型决定 key、value 是否允许为空,put 和 get 方法均用 synchronized 修饰,各个方法争抢同一个 mutex 对象的锁。
ConcurrenHashMap
ConcurrentHashMap 的锁分段技术可有效提升并发访问率。HashTable 容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问 HashTable 的线程都必须竞争同一把锁,但是假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,而可以有效提高并发访问效率,这就是 ConcurrentHashMap 所使用的锁分段技术:
首先将数据分成一段一段地存储,然后给每一段数据配一把锁;当一个线占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
- 结构
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色。HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构。一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改,必须首先获得与它对应的 Segment 锁。
- 初始化
ConcurrentHashMap 初始化方法是通过
initialCapacity、loadFactor和concurrencyLevel等几个参数来初始化 segment 数组、段偏移量 segmentShift、段掩 segmentMask 和每个 segment 里的 HashEntry 数组来实现的。
- 锁分段定位
既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过散列算法定位到 Segment。可以看到 ConcurrentHashMap 会首先使用 Wang/Jenkins hash 的变种算法对元素的 hashCode 进行一次再散列。
private static int hash(int h) { h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); }之所以进行再散列,目的是减少散列冲突,使元素能够均匀地分布在不同的 Segment 上,从而提高容器的存取效率。假如散列的质量差到极点,那么所有的素都在一个 Segment 中,不仅存取元素缓慢,分段锁也会失去意义。
并发 queue
在并发编程中,有时候需要使用线程安全的队列。如果要实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现;非阻塞的实现方式则可以使用循环 CAS 的方式来完成。
ConcurrentLinkedQueue
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会被添加到队列尾部;当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法(即 CAS 算法)来实现,该算法在 Michael & Scott 算法上进行了一些修改。
ConcurrentLinkedQueue 由 head 节点和 tail 节点组成,每个节点(Node)由节点元素(item)和指向下一个节点(next)的引用组成,节点与节点之间就是通过这个 next 关联起来,从而组成一张链表结构的队列。默认情况下 head 节点存储的元素为空,tail 节点等于 head 节点。
阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法。
1)支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。
2)支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会阻塞,等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。
JDK 7提供了7个阻塞队列,如下。
| 队列 | 说明 |
|---|---|
ArrayBlockingQueue |
一个由数组结构组成的有界阻塞队列 |
LinkedBlockingQueue |
一个由链表结构组成的有界阻塞队列 |
PriorityBlockingQueue |
一个支持优先级排序的无界阻塞队列 |
DelayQueue |
一个使用优先级队列实现的无界阻塞队列 |
SynchronousQueue |
一个不存储元素的阻塞队列 |
LinkedTransferQueue |
一个由链表结构组成的无界阻塞队列 |
LinkedBlockingDeque |
一个由链表结构组成的双向阻塞队列 |
- ArrayBlockingQueue
ArrayBlockingQueue是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证线程公平的访问队列,所谓公平访问队列是指阻塞的线程,可以按照阻塞的先后顺序访问队列,即先阻塞线程先访问队列。非公平性是对先等待的线程是非公平的,当队列可用时,阻塞的线程都可以争夺访问队列的资格,有可能先阻塞的线程最后才访问队列。为了保证公平性,通常会降低吞吐量。我们可以使用以下代码创建一个公平的阻塞队列。
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);访问者的公平性是使用可重入锁实现的,代码如下。
public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } - LinkedBlockingQueue
LinkedBlockingQueue 是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为
Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。LinkedBlockingQueue是Executors.newFixedThreadPool(int nThreads)创建线程池时采用的内部任务队列; - PriorityBlockingQueue
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列。默认情况下元素采取自然顺序升序排列。也可以自定义类实现
compareTo()方法来指定元素排序规则,或者初始化 PriorityBlockingQueue 时,指定构造参数 Comparator 来对元素进行排序。需要注意的是不能保证同优先级元素的顺序。 - DelayQueue
DelayQueue 是一个支持延时获取元素的无界阻塞队列。队列使用 PriorityQueue 来实现。队列中的元素必须实现 Delayed 接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。DelayQueue 非常有用,可以将 DelayQueue 运用在以下应用场景。
缓存系统的设计:可以用 DelayQueue 保存缓存元素的有效期,使用一个线程循环查询 DelayQueue ,一旦能从 DelayQueue 中获取元素时,表示缓存有效期到了。
定时任务调度:使用 DelayQueue 保存当天将会执行的任务和执行时间,一旦从 DelayQueue 中获取到任务就开始执行,比如 TimerQueue 就是使用 DelayQueue 实现的。
- SynchronousQueue
SynchronousQueue 是一个不存储元素的阻塞队列。每一个 put 操作必须等待一个 take 操作,否则不能继续添加元素。它支持公平访问队列。默认情况下线程采用非公平性策略访问队列。使用以下构造方法可以创建公平性访问的 SynchronousQueue,如果设置为 true,则等待的线程会采用先进先出的顺序访问队列。
SynchronousQueue 可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合传递性场景。SynchronousQueue 的吞吐量高于 LinkedBlockingQueue 和 ArrayBlockingQueue。
- LinkedTransferQueue
LinkedTransferQueue 是一个由链表结构组成的无界阻塞 TransferQueue 队列。相对于其他阻塞队列,LinkedTransferQueue 多了
tryTransfer和transfer方法。 - LinkedBlockingDeque
LinkedBlockingDeque 是一个由链表结构组成的双向阻塞队列。所谓双向队列指的是可以从队列的两端插入和移出元素。双向队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque 多了
addFirst、addLast、offerFirst、offerLast、peekFirst和peekLast等方法,以 First 单词结尾的方法,表示插入、获取(peek)或移除双端队列的第一个元素。以 Last 单词结尾的方法,表示插入、获取或移除双端队列的最后一个元素。另外,插入方法 add 等同于 addLast,移除方法 remove 等效于 removeFirst。但是 take 方法却等同于 takeFirst,不知道是不是 JDK 的 bug,使用时还是用带有 First 和 Last 后缀的方法更清楚。在初始化 LinkedBlockingDeque 时可以设置容量防止其过度膨胀。另外,双向阻塞队列可以运用在“工作窃取”模式中。
Fork/Join 框架
Fork/Join框架是 Java 7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。那么,为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用 双端队列 ,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
- 优点
充分利用线程并发操作执行任务,减少线程间的竞争切换;
- 缺点
某些情况下还是存在竞争,比如双端队列中只有一个任务时。并且此算法会消耗更多的系统资源,比如创建多个线程,多个双端队列。
使用流程
- 分割任务
- 执行任务
- 合并结果
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 310195418127112037L;
private static final int THRESHOLD = 2;// 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
// 检查任务是否正常完成
if(leftTask.isCompletedAbnormally()) {
System.out.println(leftTask.getException());
}
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算1+2+3+4
CountTask task = new CountTask(1, 4);
// 执行一个任务
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (Exception e) {
e.printStackTrace();
}
}
}
原子操作类
Java 从 JDK 1.5 开始提供了 java.util.concurrent.atomic 包(以下简称Atomic包),这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。因为变量的类型有很多种,所以在 Atomic 包里一共提供了 13 个类,属于 4 种类型的原子更新方式,分别是原子更新基本类型、原子更新数组、原子更新引用和原子更新属性(字段)。Atomic 包里的类基本都是使用 Unsafe 实现的包装类。
CAS 原子操作实现类
-
原子更新基本类型类
AtomicBooleanAtomicInteger-
AtomicLong -
原子更新数组
AtomicIntegerArrayAtomicLongArrayAtomicIntegerArray-
AtomicReferenceArray - 原子更新引用类型
要原子更新多个变量,就要使用这个原子更新引用类型提供的类。
AtomicReference原子更新引用类型AtomicReferenceFieldUpdater原子更新引用类型里的字段AtomicMarkableReference原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型
import java.util.concurrent.atomic.AtomicReference;
public class AtomicRefrenceTest {
public static AtomicReference<User> atomicReference = new AtomicReference<User>();
public static void main(String[] args) {
User user1 = new User("user1");
atomicReference.set(user1);
System.out.println(atomicReference.get());
User user2 = new User("user2");
atomicReference.compareAndSet(user1, user2);
System.out.println(atomicReference.get());
}
static class User {
private String name;
public User(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User [name=" + name + "]";
}
}
}
解决 ABA 问题
- 原子更新字段类
AtomicStampedReference
AtomicIntegerFieldUpdater
AtomicLongFieldUpdater
要想原子地更新字段类需要两步。第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法 newUpdater() 创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新类的字段(属性)必须使用 public volatile 修饰符。
以上3个类提供的方法几乎一样,所以仅以AstomicIntegerFieldUpdater为例进行讲解
public class AtomicIntegerFieldUpdaterTest {
// 创建原子更新器,并设置需要更新的对象类和对象的属性
private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "old");
public static void main(String[] args) {
// 设置柯南的年龄是 10 岁
User conan = new User("conan", 10);
// 柯南长了 1 岁,但是仍然会输出旧的年龄
System.out.println(a.getAndIncrement(conan));
// 输出柯南现在的年龄
System.out.println(a.get(conan));
}
public static class User {
private String name;
public volatile int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
}
并发工具类
jdk 提供的常用并发工具类:
- CountdownLatch
- CyclicBarrier
- Semaphore
- Phaser
CountDownLatch
CountdownLatch 用于等待多线程完成。
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class CountDownLatchTest {
// 等待 2 个线程完成再继续
static CountDownLatch latch = new CountDownLatch(2);
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(1);
latch.countDown();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(2);
latch.countDown();
}
}).start();
try {
// latch.await();//不限定超时
latch.await(3, TimeUnit.MINUTES);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
CyclicBarrier 同步屏障
每个线程在到达一个屏障点(同步点)时都等待,一直到所有的线程都到达了这个屏障点后,屏障才打开,让所有这些线程一起返回。
单个线程调用 CyclicBarrier#await() 方法,表明其到达了屏障,然后处于阻塞状态,直至所有线程都到达屏障才放行。
import java.util.concurrent.BrokenBarrierException; import java.util.concurrent.CyclicBarrier; public class CyclicBarrierTest { static CyclicBarrier barrier = new CyclicBarrier(4); // static CyclicBarrier barrier2 = new CyclicBarrier(4, new Runnable() { // @Override // public void run() { // System.out.println("all finished. 此处可以汇总各个线程的结果"); // } // }); public static void main(String[] args) { for (int i = 0; i < 3; i++) { final int t = i; new Thread(new Runnable() { @Override public void run() { try { System.out.println(t); barrier.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } } }).start(); } try { barrier.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } System.out.println("ok"); } }
CountdownLatch 与 CyclicBarrier
CyclicBarrier 与 CountDownLatch 都可以实现线程间等待,但后者比前者更为灵活:
- 前者的计数器只能使用一次,后者可以使用
reset()重置 - 后者可以获取阻塞的线程数量
Semaphore 并发线程控制
Semaphore 可以控制同时访问特定线程的线程数量,保证合理使用公共资源,适用于流控调度等场景。
public class SemaphoreTest {
private static final int THREAD_COUNT = 30;
private static ExecutorServicethreadPool = Executors.newFixedThreadPool(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (inti = 0; i< THREAD_COUNT; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
s.acquire();
System.out.println("save data");
s.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
threadPool.shutdown();
}
}
Phaser
支持分阶段并发,一个可重用的同步屏障,功能上类似 CyclicBarrier 和 CountDownLatch,但是支持更灵活的使用方式。
和其他屏障工具类不同,随着时间变化注册到 Phaser 上的同步线程会变化,任何时候都任务可以注册到 Phaser 并且可以随意解除注册。
A Phaser may be used instead of a CountDownLatch to control a one-shot action serving a variable number of parties. The typical idiom is for the method setting this up to first register, then start the actions, then deregister, as in:
void runTasks(List<Runnable> tasks) {
final Phaser phaser = new Phaser(1); // "1" to register self
// create and start threads
for (final Runnable task : tasks) {
phaser.register();
new Thread() {
public void run() {
phaser.arriveAndAwaitAdvance(); // await all creation
task.run();
}
}.start();
}
// allow threads to start and deregister self
phaser.arriveAndDeregister();
}}
One way to cause a set of threads to repeatedly perform actions for a given number of iterations is to override onAdvance:
void startTasks(List<Runnable> tasks, final int iterations) {
final Phaser phaser = new Phaser() {
protected boolean onAdvance(int phase, int registeredParties) {
return phase >= iterations || registeredParties == 0;
}
};
phaser.register();
for (final Runnable task : tasks) {
phaser.register();
new Thread() {
public void run() {
do {
task.run();
phaser.arriveAndAwaitAdvance();
} while (!phaser.isTerminated());
}
}.start();
}
phaser.arriveAndDeregister(); // deregister self, don't wait
}}
If the main task must later await termination, it may re-register and then execute a similar loop:
// ...
phaser.register();
while (!phaser.isTerminated())
phaser.arriveAndAwaitAdvance();
Related constructions may be used to await particular phase numbers in contexts where you are sure that the phase will never wrap around Integer.MAX_VALUE. For example:
void awaitPhase(Phaser phaser, int phase) {
int p = phaser.register(); // assumes caller not already registered
while (p < phase) {
if (phaser.isTerminated())
// ... deal with unexpected termination
else
p = phaser.arriveAndAwaitAdvance();
}
phaser.arriveAndDeregister();
}}
To create a set of n tasks using a tree of phasers, you could use code of the following form, assuming a Task class with a constructor accepting a Phaser that it registers with upon construction. After invocation of build(new Task[n], 0, n, new Phaser()), these tasks could then be started, for example by submitting to a pool:
void build(Task[] tasks, int lo, int hi, Phaser ph) {
if (hi - lo > TASKS_PER_PHASER) {
for (int i = lo; i < hi; i += TASKS_PER_PHASER) {
int j = Math.min(i + TASKS_PER_PHASER, hi);
build(tasks, i, j, new Phaser(ph));
}
} else {
for (int i = lo; i < hi; ++i)
tasks[i] = new Task(ph);
// assumes new Task(ph) performs ph.register()
}
}}
Exchanger 线程间数据交换
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger 用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过 exchange 方法交换数据,如果第一个线程先执行 exchange 方法,它会一直等待第二个线程也执行 exchange 方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
Exchanger 可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两人的数据,并使用交叉规则得出 2 个交配结果。
Exchanger 也可以用于校对工作,比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用 AB 岗两人进行录入,录入到 Excel 之后,系统需要加载这两个 Excel,并对两个 Excel 数据进行校对,看看是否录入一致,代码如下:
public class ExchangerTest {
private static final Exchanger<String> exgr = new Exchanger<String>();
private static ExecutorService threadPool = Executors.newFixedThreadPool(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String A = "银行流水A";// A录入银行流水数据
exgr.exchange(A);
} catch (InterruptedException e) {
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String B = "银行流水B";// B录入银行流水数据
String A = exgr.exchange(B);
System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:" + A + ",B录入是:" + B);
} catch (InterruptedException e) {
}
}
});
threadPool.shutdown();
}
}
如果两个线程有一个没有执行 exchange() 方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用 exchange(V x,longtimeout,TimeUnit unit) 设置最大等待时长。
线程池
优点
- 降低资源消耗
- 提高响应速度
- 提高线程可管理性,拒绝野生线程
任务执行流程
使用 ThreadPoolExecutor 创建一个线程池:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler){
}
// 具体参数含义详见 jdk 文档!
- 用于保存任务的
workQueue队列主要类型-
ArrayBlockingQueue:
基于数组结构的有界阻塞队列
-
LinkedBlockingQueue:
基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高于 ArrayBlockingQueue。
Executors.newFixedThreadPool()使用了这个队列。 -
SynchronousQueue:
一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,
Executors.newCachedThreadPool()使用了这个队列。 -
PriorityBlockingQueue
一个具有优先级的无限阻塞队列。
-
可以分析源码,submit() 方法内部也还是调用了 execute()。
- 提交任务
ThreadPoolExecutor在执行execute()方法提交任务时,逻辑大意如下:
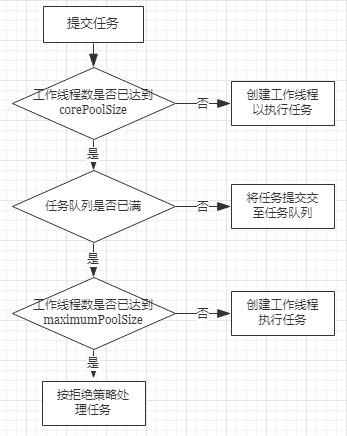
ThreadPoolExecutor 执行 execute() 方法分下面 4 种情况。
- 1)如果当前运行的线程(即便是 idle 状态)少于 corePoolSize,则创建新线程来执行任务(这一步骤需要获取全局锁)。
- 2)如果运行的线程等于或多于 corePoolSize,则将任务加入 BlockingQueue。
- 3)如果无法将任务加入 BlockingQueue(队列已满),则创建新的线程来处理任务(这一步骤需要获取全局锁)。
- 4)如果创建新线程将使当前运行的线程超出 maximumPoolSize,任务将被拒绝,并调用
RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor 采取上述步骤的总体设计思路,是为了在执行 execute() 方法时,尽可能地避免获取全局锁带来的性能瓶颈。在 ThreadPoolExecutor 完成预热之后(当前运行的线程数大于等于 corePoolSize),几乎所有的 execute() 方法调用都是执行步骤 2,以尽量避免获取全局锁。
- 任务提交和执行流程
- ThreadPoolExecutor 内部类 Worker 用于执行具体任务
HashSet<Worker> workers用于存储各个 worker 对象- 提交任务过程中判断并初始化 worker 实例,也就是一个工作线程
- 每个 worker 都一直获取待执行的任务,保证任务完成后返回执行结果。
- 具体任务执行过程中
- worker 会捕捉异常,保障
afterExecute(Runnable r, Throwable t)可以被执行 - 但最终会抛出捕捉到的异常,导致 worker 跳出循环,无法获取新的任务
- worker 会捕捉异常,保障
主要流程就在如下代码,建议配合 debug 跟踪:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {// 一直获取任务
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
关闭
可以通过调用线程池的 shutdown 或 shutdownNow 方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的 interrupt 方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow 首先将线程池的状态设置成 STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而 shutdown 只是将线程池的状态设置成 SHUTDOWN 状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown 方法就会返回 true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用 isTerminated 方法会返回 true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用 shutdown 方法来关闭线程池,如果任务不一定要执行完,则可以调用 shutdownNow 方法。
选型
性质不同的任务可以用不同规模的线程池分开处理。例如 CPU 核数为 N,CPU 密集型任务应配置尽可能小的线程,如配置 N + 1 个线程的线程池。由于 IO 密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如 2 * N。混合型的任务,如果可以拆分,将其拆分成一个 CPU 密集型任务和一个 IO 密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过 Runtime.getRuntime().availableProcessors() 方法获得当前设备的 CPU 个数。
建议使用有界队列。有界队列能增加系统的稳定性和预警能力。
监控预警
如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。可以通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性。
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于 taskCount。
- largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减。
- getActiveCount:获取活动的线程数。
通过扩展线程池进行监控。可以通过继承线程池来自定义线程池,重写线程池的 beforeExecute、afterExecute 和 terminated 方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。
Executor 框架
Executors
Executor 框架最核心的类是 ThreadPoolExecutor,它是线程池的实现类,主要由下列 4 个组件构成。
- corePoolSize:核心线程池的大小。
- maximumPoolSize:最大线程池的大小。
- BlockingQueue:用来暂时保存任务的工作队列。
- RejectedExecutionHandler:当 ThreadPoolExecutor 已经关闭或已经饱和时(达到了最大线程池大小且工作队列已满),execute() 方法将要调用的 Handler。
分类
通过 Executors 可以创建的 ExecutorService 分为如下几种:
- newFixedThreadPool 内部采用无界队列,可能会 OOM
- newSingleThreadExecutor 内部采用无界队列,可能会 OOM
- newSingleThreadScheduledExecutor 实现定时的单工作线程的线程池
- newCachedThreadPool 会根据需要创建新线程的线程池
- newScheduledThreadPool 用来执行定时任务
- newWorkStealingPool 采用工作窃取的线程池
在实际业务编码中建议手动构建 ThreadPoolExecutor 对象,掌握每一个参数的含义,避免采用 Executors 生成,减少出错机会。
(゜-゜)つロ 参考并致谢《Java并发编程的艺术》