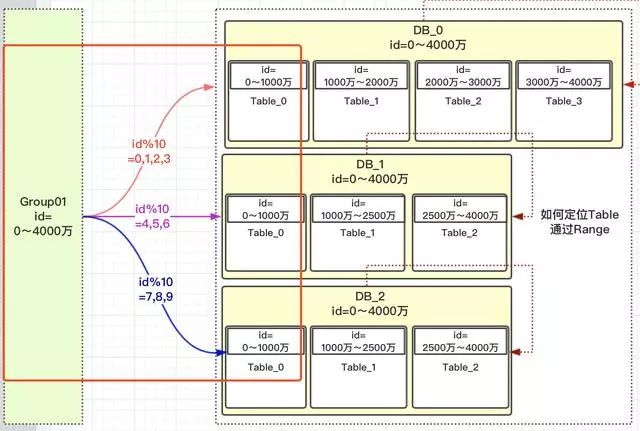
预计1年后用户数据10亿条,写QPS约5000,读QPS30000,可以设计按UID纬度进行散列,分为4个库每个库32张表,单表数据量控制在KW级别;
如何对容量进行评估,如何适当分库分表来保证未来服务的可扩展性
分库分表
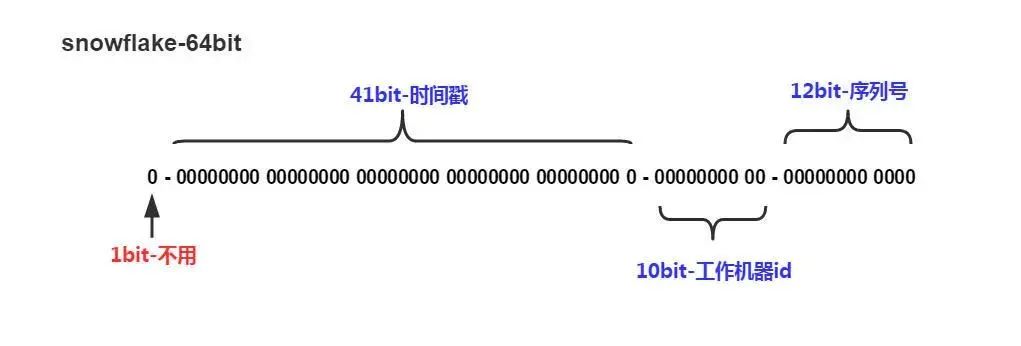
全局 id 生成算法一般包括:数据库自增id、UUID(128位)、COMB组合(10字节GUID+6字节时间,实现有序),SnowFlake算法
分片策略
基础分片规则整理如下:
| 策略 | 说明 |
|---|---|
| 根据业务 Range 分片计算 | 根据业务字段取范围 |
| 根据业务 ID 取模计算 | 涉及到数据迁移;一定要考虑且验证好分片路由效果,避免数据倾斜(dbNum 与 tableNum 互质) |
| 一致性 Hash 算法 | 需要考虑 |
// 一个较好的方案:解决数据偏斜的问题,只要Hash值足够均匀,那么理论上分配序号也会足够平均,每个库和表中的数据量也能保持较均衡的状态
public static ShardCfg shard2(String userId) {
// ① 算Hash
int hash = userId.hashCode();
// ② 总分片数
int sumSlot = DB_CNT * TBL_CNT;
// ③ 分片序号
int slot = Math.abs(hash % sumSlot);
// ④ 重新修改二次求值方案
int dbIdx = slot / TBL_CNT ;
int tblIdx = slot % TBL_CNT ;
return new ShardCfg(dbIdx, tblIdx);
}
弹性扩容
一般扩容流程:
Step1:按照新旧分片规则,对新旧数据库进行双写。
Step2:将双写前按照旧分片规则写入的历史数据,根据新分片规则迁移写入新的数据库。
Step3:将按照旧的分片规则查询改为按照新的分片规则查询。
Step4:将双写数据库逻辑从代码中下线,只按照新的分片规则写入数据。
Step5:删除按照旧分片规则写入的历史数据。