分布式锁本质也是锁,目的是采用加锁的方式实现公共资源在分布式系统间的并发情景下的正确维护。
特性
分布式锁应该具备哪些特性呢?
| 特性 | 说明 |
|---|---|
| 互斥性 | 保证在资源争抢过程中只有一个节点能获取锁 |
| 防死锁 | 防止在争抢过程中出现死锁无法释放,阻塞其他业务线程 |
| 可重入 | 避免获取到锁的节点重新再获取同一个锁 |
| 阻塞和自旋 | 基于效率考虑,自旋锁适用于临界区操作耗时短的场景; 阻塞锁适用于临界区操作耗时长的场景。 |
| 高并发性能 | 高并发下性能稳定 |
| 公平性 | 最好能支持公平锁 |
解决方案
一般的常用解决方案包括:数据库、redis、zookeeper、Memcached 等。
基于数据库
采用数据库锁的机制,可以采用乐观锁和悲观锁。
- 乐观锁实现
一般是通过设置 version 字段,先查询数据再更新数据,更新时限定 version 版本,如:
SELECT id, resource, state, version
FROM t_resource
WHERE state = 1 AND id = 5780;
UPDATE t_resoure
SET state = 2, version = 27, update_time = now()
WHERE id=5780 AND state = 1 AND version = 26;
若 update 返回更新了一行数据说明更新成功,否则就是资源已被占用。
此方案需先查询再更新,高并发下增加数据库开销;需考虑查询结果为空时进行记录初始化;不推荐在存储过程中实现逻辑。
- 悲观锁
select * from order_table where id = 'xxx' for update;
这种方式下需要自己考虑锁超时,加事务等等,性能局限于数据库,一般对比缓存来说性能较低。对于高并发的场景并不是很适合。
基于 Redis
setnx 命令
基于 setnx 命令的分布式锁在实现时,需要考虑较多的业务场景:
- 如何实现锁续约
- 短时间未完成业务需保证锁不被打断释放
- 在 Redis Sentinel 架构下如何保证始终对应同一个节点
- 获取全局锁成功后,异常导致未释放锁
- 获取全局锁后同一个线程怎么实现可重入
- 单次加锁失败是否支持重试、判断异常情况
# redis 命令加锁
SET resource_name my_random_value NX PX 30000
# lua 脚本释放锁
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
Redlock 算法
Redis 作者 antirez 基于分布式环境下提出了一种更高级的分布式锁的实现方式:Redlock。这个算法适用于复杂高可用架构下的分布式锁操作,主要包括如下步骤(假设 N 个节点):
- 获取当前时间
- 在所有节点中获取锁。需考虑单个节点的操作超时限制。
- 计算出步骤 2 的总耗时时间,当且仅当在有效时间内获取到了大多数节点(临界值 N/2+1)的锁,才认为加锁成功。
- 若判定加锁成功,锁有效期需减去加锁耗时
- 若加锁失败则需解除所有节点的锁
关于 Redisson 实现:
- 使用 lua 脚本
- value 采用 uuid + threadId
# 加锁
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
# 释放锁
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil
end;
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1
end;
return nil;
由于 GC 的 STW 可能存在问题如下:
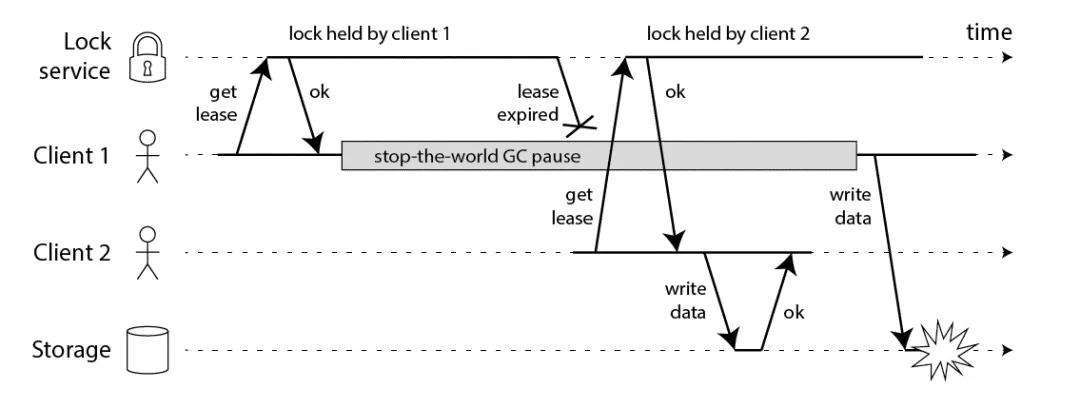
以及节点时钟跳跃、长时间网络 I/O,都是潜在的危险。
锁续约机制
参考官方 doc:8.1. 可重入锁(Reentrant Lock)
如果负责储存某些分布式锁的某些 Redis 节点宕机以后,而且这些锁正好处于锁住的状态时,这些锁会出现锁死的状态。为了避免这种情况的发生,Redisson 内部提供了一个监控锁的 watchDog,它的作用是在 Redisson 实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改
Config.lockWatchdogTimeout来另行指定。另外 Redisson 还通过加锁的方法提供了
leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
打开 RedissonLock 类,可以找到其内部私有方法:scheduleExpirationRenewal(final long threadId),详细的续约逻辑就是在这里:
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {
task.cancel();
}
}
可以看到是先判断一下并发 map 里是否有当前节点,然后再执行续约任务,间隔是 30/3=10 秒钟,任务内容也是 lua 脚本。
基于 ZooKeeper
ZooKeeper是一种“分布式协调服务”,可以在分布式系统中共享配置,协调锁资源,提供命名服务等。ZK 中的节点(以下简称ZNode)非常适合用于存储少量的状态和配置信息,为读多写少的场景所设计,基于临时节点即可实现分布式锁。
多个session都去创建同一个distribute_lock节点,只会有一个创建成功的session。相当于只有该session获取到锁,其他session没有获取到锁。在该成功获锁的session失效前,锁将会一直阻塞住。session失效时,节点会自动被删除,锁被解除。
可以使用 Apache Curator 框架实现。
// 部分代码如下:
private static CuratorFramework curatorFramenork;
private static InterProcessMutex lock;
static String path = "/wz/lock";
static {
curatorFramework = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
lock = new InterProcessMutex(curatorFramework, path);
curatorFramework.start();
}
public static void lock() throws Exception {
lock.acquire();
}
public static void release() throws Exception {
lock.release();
}
public static void lock(long time, TimeUnit timeUnit) throws Exception {
lock.acquire(time, timeUnit);
}
加锁的流程具体如下:
首先进行可重入的判定:这里的可重入锁记录在 ConcurrentMap<Thread, LockData>threadData 这个 Map 里面。 如果 threadData.get(currentThread)是有值的那么就证明是可重入锁,然后记录就会加 1。 我们之前的 MySQL 其实也可以通过这种方法去优化,可以不需要 count 字段的值,将这个维护在本地可以提高性能。
然后在我们的资源目录下创建一个节点:比如这里创建一个 /0000000002 这个节点,这个节点需要设置为 EPHEMERAL_SEQUENTIAL 也就是临时节点并且有序。
获取当前目录下所有子节点,判断自己的节点是否位于子节点第一个。
如果是第一个,则获取到锁,那么可以返回。
如果不是第一个,则证明前面已经有人获取到锁了,那么需要获取自己节点的前一个节点。 /0000000002 的前一个节点是 /0000000001,我们获取到这个节点之后,再上面注册 Watcher(这里的 Watcher 其实调用的是 object.notifyAll(),用来解除阻塞)。
object.wait(timeout) 或 object.wait():进行阻塞等待,这里和我们第 5 步的 Watcher 相对应。
解锁的具体流程:
首先进行可重入锁的判定:如果有可重入锁只需要次数减 1 即可,减 1 之后加锁次数为 0 的话继续下面步骤,不为 0 直接返回。
删除当前节点。
删除 threadDataMap 里面的可重入锁的数据。
得益于 ZK 的 session 机制,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁,依靠Session(心跳)来维持锁的持有状态。得益于 ZK 的 watch 机制,在获取锁失败之后可以等待锁重新释放的事件,让客户端对锁的使用更加灵活。性能上来讲不如 Redis。
基于 Memcached
可以使用 Memcached 的 add() 方法做分布式锁。
# 如果 add 的 key 已经存在,则不会更新数据(过期的 key 会更新),之前的值将仍然保持相同,并且您将获得响应 NOT_STORED。
add key flags exptime bytes [noreply]
value
测试实例
// 模拟初始化 Concurrency 个线程,并同时执行相同的 task
public void invokeAllTask(ConcurrencyRequest request, Runnable task) {
final CountDownLatch startCountDownLatch = new CountDownLatch(1);
final CountDownLatch endCountDownLatch = new CountDownLatch(request.getConcurrency());
for (int i = 0; i < request.getConcurrency(); i++) {
Thread t = new Thread(() -> {
try {
startCountDownLatch.await();
try {
task.run();
} finally {
endCountDownLatch.countDown();
}
} catch (Exception ex) {
log.error("异常", ex);
}
});
t.start();
}
startCountDownLatch.countDown();
try {
endCountDownLatch.await();
} catch (InterruptedException ex) {
log.error("线程异常中断", ex);
}
}