分布式理论
CAP 定理
CAP 定理由加州大学伯克利分校 Eric Brewer 教授提出来的,他指出WEB服务无法同时满足以下 3 个属性:
| 特性 | 描述 |
|---|---|
| 一致性(Consistency) | 客户端知道一系列的操作都会同时发生(生效) |
| 可用性(Availability) | 每个操作都必须以可预期的响应结束 |
| 分区容错性(Partition tolerance) | 即使出现单个组件无法可用,操作依然可以完成 |
BASE 理论
BASE 理论是对 CAP 定理的进一步扩充,其含义为:
| 特性 | 描述 |
|---|---|
| Basically Available | 基本可用 |
| Soft state | 软状态 |
| Eventually consistent | 最终一致性 |
BASE 理论是对 CAP 中的 一致性和 可用性 进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
分布式事务解决方案
- 强一致性解决方案
- 最终一致性解决方案
要结合业务自身的一致性需求,选择恰当的方案。数据一致性“能力”越强的方案其开发维护成本越高,损耗越大;适合系统的方案才是好方案。
强一致性
两阶段提交
Two phase commit, 2PC.
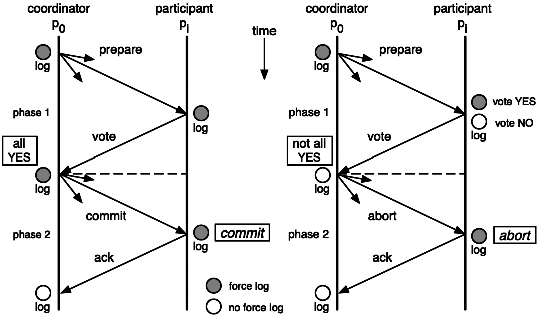
XA 规范下产生了 2PC、3PC 等实现。
若由于网络问题导致部分参与者未提交,就会数据不一致;协调者再发出提交消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了,那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
更多可参考 《Paxos Made Simple》论文。
三阶段提交
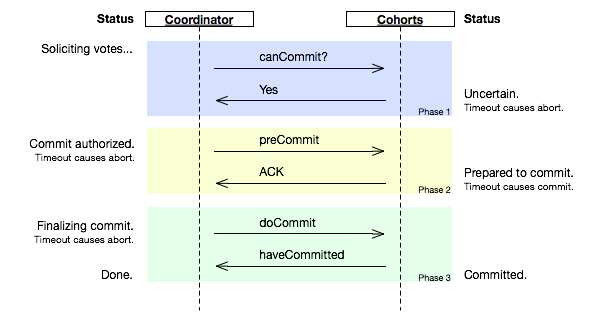
针对 2PC 的不足, 3PC 引入了超时机制和新的准备阶段:
- 1、引入超时机制。同时在协调者和参与者中都引入超时机制。
- 2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
3PC 主要解决单点故障问题,以及减少阻塞。一旦参与者无法及时收到来自协调者的信息便会默认执行 commit,而不是一直持有事务资源并处于阻塞状态。
但是这种机制同样也会导致数据一致性问题:若由于网络原因协调者发送的 abort 响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit 操作,就会和其他接到 abort 命令并执行回滚的参与者之间存在数据不一致的情况。
最终一致性
TCC
TCC将事务分为Try,Confirm,Cancel三个阶段。
| Try | 尝试执行业务,预留资源 |
| Confirm | 确认执行业务,使用 Try 阶段资源 |
| Cancel | 取消执行业务,释放 Try 阶段预留的资源 |
过程中基本没有涉及到加锁的操作,主要要求:保证 TCC 过程的完整性、 CC 的幂等性。但是 TCC 对业务侵入大改造成本高。
本地消息表
将事务消息存储到表中进行托底,保证消息收发和本地事务的数据写入是原子性的,同时消息处理的接口具有幂等性。
实际应用中根据不同业务场景可以进行适当的简化,例如:只要接收到 message 并写入本地表成功,就必须保证消费成功,极端情况下引入业务报警人工处理;发起方本地取消一个事务,则需要补发一个 cancel 的 message 给消费方,通知其进行补偿(也可以认为这个 cancel 是新的 message 通知,模糊掉“补偿”这个概念);
同样需要保证接口幂等性。
SAGA 模型
此处不多描述。
MQ 消息
基于 MQ 消息的分布式事务常常是结合前面提到的本地消息表,以 MQ 作为可靠的 message 传递渠道,进行服务间的交互,大致业务逻辑不再赘述。此处介绍下另一种事务性的 MQ 消息,RocketMQ。
如 Apache RocketMQ 事务消息 简介里所述,事务消息可以认为是实现分布式系统间最终一致性的 2PC 实现。但是具有如下限制:
事务消息没有批量支持、定时任务支持;为避免积压默认限制检测消息收发 15 次;间隔一段时间后才会检测事务状态;事务消息可能会被消费多次;消息重发可能会失败;