Redis 作为一款开源的 NoSQL 产品,在系统架构中起到了十分重要的作用。本文整理 Redis 的基础知识,并在此基础上引入了系统架构中常见的缓存问题和解决方案。
优势/速度快的原因
Redis 之所以这样快,主要原因是以下几点:
- 纯内存操作
- 单线程操作,避免线程切换
- 单线程处理所有 redis-cli 请求
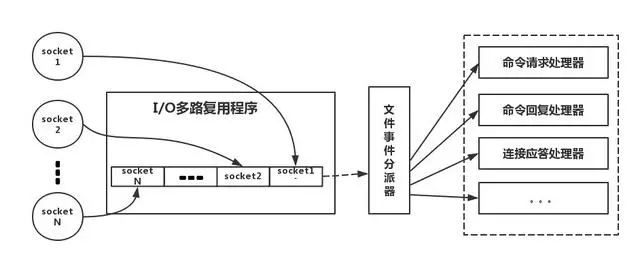
- 采用 I/O 多路复用机制,非阻塞 I/O
- 服务端运行一个 IO 多路复用程序
- 同时接收到多个网络请求
- 将这些请求置于队列
- 转发请求到对应类型的命令处理器
- 封装了底层的 select、epoll、kqueue、evport 等 IO 多路复用函数
- 编译时优选选择时间复杂度低 O(1) 的函数
- 最差情况就是选择 select,O(n),最多 1024 个 FD
- 采用 Reactor 的方式来实现文件事件处理器
- 文件事件处理器使用 I/O 多路复用模块同时监听多个 FD
- 当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器
- 数据结构简单
主要数据类型
- String
- value 理论上最大是 512M
- List
- 链表,底层基于 quicklist(ziplist+linkedlist)
- 双向链表
- 既可以作为栈也可以作为队列。
- 可以实现消息队列,时间轴
- 常用命令
- L(R)PUSH, L(R)POP
- BL(R)POP
- LRANGE
- 链表,底层基于 quicklist(ziplist+linkedlist)
- Hash
- 是一个 String 类型的键值对映射表
- 它的添加和删除效率是平均的。
- 适合用于存储对象,相比于将对象序列化成字符串值存储的方式而言占用更少的内存,并且可以更方便的存取整个对象。
- 和 java 的 HashMap 类似;可以只修改某一项属性值。
- 常用命令
- HMSET KEY K1 V1 K2 V2…
- HGET KEY K1
- HGETALL KEY
- 是一个 String 类型的键值对映射表
- Set
- String类型的无序集合,key不重复,支持求交集/并集/差集。
- 可以实现已关注/粉丝/共同关注/二度好友/抽奖/赞/踩/标签 SRANDMEMBER
- 常用命令
- SADD KEY v1 v2 v3,SADD KEY:TAG V1 V2 V3
- SMEMBER KEY(:TAG), SISMENBER KEY V “查看成员,验证是否为成员”
- SINTER
- String类型的无序集合,key不重复,支持求交集/并集/差集。
- ZSet(Sorted Set)
- 增加权重的 Set
- 基于 哈希表 + skiplist 实现
- 哈希表存储成员到 score 的映射
- 跳表存储所有成员
- 元素修改后会重排序
- 基于 哈希表 + skiplist 实现
- 常用命令
- ZADD KEY K1 V1
ZRANGE(byscore) KEY 0 -1 <withscores>
- 增加权重的 Set
- bitmap
- 在 string 上存储不同 offset 对应的 byte 值(0,1)
- SETBIT
- 长度上限越大,初始化越耗时
- 使用场景:bitset 用户签到,bitop 统计活跃用户
key 过期策略
Redis 的 key 过期策略采用主动 + 被动的方式。
-
主动过期
当 key 被 get 时若发现已过期,这个 key 就会被删除。
-
被动过期
Redis 有一个定时任务每秒执行 10 次,流程如下:
- 随机取 20 个已设置过期时间的 key
- 删除已过期的 key
- 若本过程中有四分之一以上的 key 是已过期,则重新执行步骤 1
极端情况下,已过期但未被删除的 key 数量为每秒写入 key 总数的四分之一。
配置优化方案
- 建议设置 maxmemory-policy 为 volatile-lru
- 3.0 版本默认是 noeviction 会阻塞清理内存导致延迟。
- volatile-lru : remove the key with an expire set using a LRU algorithm
- maxmemory-policy 数据驱逐策略,优化目的:保证热点数据占据内存
- volatile-lru:从已设置过期时间的数据中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据中任意选择数据淘汰
- allkeys-lru:从数据中挑选最近最少使用的数据淘汰
- allkeys-random:从数据中任意选择数据淘汰
- no-enviction:禁止淘汰数据
缓存更新的策略
- cache aside
- 写:先写库再删缓存(需确保删除失败)
- 读:先读缓存,未命中则读库再set回缓存”
- 经典思想 write through、write back
- 缓存击穿、穿透、雪崩
- 缓存击穿(某个热点 key 失效)
- 缓存穿透(查询不存在的数据)
- 定时任务预热
- 缓存 key 过期时间,不删除数据,
- get -> judge -> set
- timerTask update
- 缓存空值(必须设置 timeout)
- 缓存 miss -> 分布式锁 -> 再次判断缓存 miss -> 查db -> 结果写入 cache(无数据则存 null)
- 布隆过滤器
- 准确判断某个数据:一定不存在、可能存在
- 缓存雪崩(大量数据同时失效/宕机)
- 事前
- 主从 + 哨兵
- redis cluster
- 事发
- 失效时间错开(特定较小范围内随机偏差)
- ehcache + hystrix 限流
- 漏桶,令牌桶 + 降级
- guava rate limiter
- 针对缓存同时失效的情况
- 设置数据不失效
- 业务端获取缓存后先判断当前时间
- 判断过期则提交更新异步任务
- 按上述其余逻辑执行
- 事后
- redis 持久化
- 事前
- 一致性 hash
- 缓存无底洞现象
- 事务
- MULTI、EXEC、DISCARD、WATCH
- 发布/订阅
- 可用于较简单的实时消息系统
持久化
待整理新:
https://mp.weixin.qq.com/s/mIc6a9mfEGdaNDD3MmfFsg
- RDB snapshot
- 定时存储内存数据快照到文件
- 优点
- 单日志文件、按时间点存储内存快照
- 方便数据恢复
- 提升程序性能(只需子线程写入 snapshot 到文件)
- 较大数据下恢复速度比 AOF 快
- 默认压缩数据
- 缺点
- 数据备份方式不灵活,极端情况会丢失数据
- fork 子进程耗时,导致 redis 阻塞
- 生成 dump 流程
- fork子进程创建rdb文件,生成后替换旧的文件
save <seconds> <changed-keys>- 注释掉即不存储
- save “” 即忽略之前 save 设置
- AOF append-only-mode
- 存储记录 redis 指令,支持日志文件动态调整大小
- 主线程每次进行 AOF 先对比上次 fsync 成功的时间
- 如果距上次不到 2s,主线程直接返回
- 如果超过 2s,则主线程阻塞直到 fsync 同步完成。
- 优点
- 灵活的备份策略 appendfsync always/no/everysec(默认)
- 日志文件是 append only,极端情况下写入中断可以通过 redis-check-aof 修复
- 文件较大时手动执行
BGREWBGREWRITEAOF(默认会自动触发执行) - 日志文件太大时可以异步重写,由新的线程重写日志,原写入操作不受影响
- 文件格式易懂,极端 flushall 情况下 AOF 没重写仍可以通过修改 AOF 再重启以恢复内存
- 缺点
- 文件较大
- 系统负载较高,持续写入 TPS 较低
- fsync 太慢导致阻塞
- 监控 info persistence 中的 aof_delayed_fsync
- AOF 极低概率存在 bug
- RDB 和 AOF 配置可以同时开启
- 当 redis 重启时会优先采用 AOF 日志重建内存数据
redis 与 fork 机制
- 官网 FAQ 的 copy-on-write (COW) mechanism 介绍:
Redis background saving schema relies on the copy-on-write semantic of fork in modern operating systems:
Redis forks (creates a child process) that is an exact copy of the parent. The child process dumps the DB on disk and finally exits. In theory the child should use as much memory as the parent being a copy, but actually thanks to the copy-on-write semantic implemented by most modern operating systems the parent and child process will share the common memory pages. A page will be duplicated only when it changes in the child or in the parent. Since in theory all the pages may change while the child process is saving, Linux can’t tell in advance how much memory the child will take, so if the overcommit_memory setting is set to zero fork will fail unless there is as much free RAM as required to really duplicate all the parent memory pages, with the result that if you have a Redis dataset of 3 GB and just 2 GB of free memory it will fail.
Setting
overcommit_memoryto 1 tells Linux to relax and perform the fork in a more optimistic allocation fashion, and this is indeed what you want for Redis.
官网解读介绍链接
- 关于 Redis 和 Fork 简单整理如下:
父进程通过 fork 操作可以创建子进程;子进程创建后,父子进程共享代码段,不共享进程的数据空间,但是子进程会获得父进程的数据空间的副本。
在操作系统 fork 的实际实现中,基本都采用了写时复制技术,即在父/子进程试图修改数据空间之前,父子进程实际上共享数据空间。但是当父/子进程的任何一个试图修改数据空间时,操作系统会为修改的那一部分(内存的一页)制作一个副本。虽然 fork 时子进程不会复制父进程的数据空间,但是会复制父进程的内存页表(页表相当于内存的索引、目录);父进程的数据空间越大、内存页表越大,fork 时复制耗时也会越多。
在 Redis 中,无论是 RDB 持久化的 bgsave,还是 AOF 重写的 bgrewriteaof,都需要 fork 出子进程来进行操作。如果 Redis 内存过大,会导致 fork 操作时复制内存页表耗时过多;而 Redis 主进程在进行 fork 时,是完全阻塞的,也就意味着无法响应客户端的请求,会造成请求延迟过大。对于不同的硬件、不同的操作系统,fork 操作的耗时会有所差别。可以通过执行命令 info stats 查看 latest_fork_usec 的值,单位为微秒。
实际部署
主从复制
可以搭配 Keepalived 做高可用。
- 实现机制
- master 间断发送(slave发起请求)更新命令给 slave 节点
- master 和 slave 连接中断后,slave 重试发起增量同步请求
- master 维护内部缓存区的 backlog
- 若部分重新同步请求不可能,slave 则申请全量重新同步;
- master会采用较复杂的机制来实现内存快照的发送和持续更新
- 要点
- 异步机制,slave 发送同步进度确认
- 一个 master 可以对应多个 slave
- slave 与 slave 之间可以相互通讯,以及串联部署。新版本下所有 slave 会接收相同的同步数据
- master 端的同步是非阻塞的
- slave 端的同步几乎都是非阻塞的,当 slave 删除旧数据并加装新数据时会阻塞
- 具体流程
- master 内部维护<Replication ID, offset>
- redis 重启时或者升级为 master 时生成一个 replication ID;
- 版本相同的主从实例具有相同的 replication ID
- slave 提升成 master 后会有两个 Replication ID,方便其他 slave 连接到自身时不必进行全量更新
- slave 发送
PSYNC <replication-id> <offset>给 master- 旧版的 SYNC 不建议再使用
- master 判断请求命令,是否可以实现增量同步
- 全量同步,master 执行 bgsave 发送内存文件给 slave
- 增量同步,master 将缓冲区的 backlog 发送给 slave
- 此时将新产生的待发送数据放到缓存队列中
- master 内部维护<Replication ID, offset>
哨兵 sentinel
是官方推荐高可用方案,可实现故障切换。
集群 cluster
版本要求3.0以上。
- 自动分片 crc16(key)%16384 2^14
- 未采用一致性哈希算法
- 虚拟槽分区,共 2 ^ 14 = 16384 个虚拟槽
- 解耦数据与节点关系,节点自身维护槽映射关系,分布式存储
- 新增节点时,只需要把其他节点的某些哈希槽挪到新节点
- 移除节点时,只需要把节点上的哈希槽挪到其他节点
- 故障容忍,每个节点都维护多个槽
- 主节点无法连接集群后,集群将会启用从节点;主节点会停止写命令并返回错误
- 集群中每个节点中都是一主多从
- 备份节点的重要性
- a、一个集群里面有M1、M2、M3三个节点,其中节点 M1包含 0 到 5500号哈希槽,节点M2包含5501 到 11000 号哈希槽,节点M3包含11001 到 16384号哈希槽。如果M2宕掉了,就会导致5501 到 11000 号哈希槽不可用,从而使整个集群不可用。
- b、一个集群里面有 M1-S1、M2-S2、M3-S3 六个主从节点,其中节点 M1 包含 0 到 5500 号哈希槽,节点 M2 包含 5501 到 11000 号哈希槽,节点 M3 包含 11001 到 16384 号哈希槽。如果是 M2 宕掉,集群便会选举 S2 为新节点继续服务,整个集群还会正常运行。当M2、S2都宕掉了,这时候集群就不可用了。”
- 不能保证数据的强一致性
- 集群采用异步写实现 M1 同步数据给 S1
- 出现网络分区后导致 S1 升级为 master, M1 的待同步数据丢失;
- 网络分区出现后,在 node timeout 时间内允许客户端写数据到 M1,超时后选出新的 master
- 服务端口为 N,则集群通讯端口为 N + 10000
- 采用 hash tags 保证待处理的 key 集合均位于同一个哈希槽
- “this{foo}key 和 another{foo}key”
- 不支持 select database
- 默认是 0
运维相关
- 避免过度依赖单一中间件
- 分片
- 应用层抽象
- 减小缓存数量量大小
- 防止主从全量同步 hang 住
- 防止 rdb、aof 太大 hang 住/超限
- 执行 BGREWRITEAOF 导致 hang 住
- 可以的话关闭 master 的持久化
- 某个 slave 开启持久化
- 做好业务与 redis 实例中间的隔离
- 不同业务避免公用相同 redis 实例
- 防止不同业务打垮 redis 而影响其他业务
- 危险命令
- 对于危险命令采用 rename-command 重命名
keys正则查找操作不当导致 hang 住- 改用
scan
- 改用
- flushdb
- flushall
- config
- 必须确认命令的时间复杂度
- redis commands
- O(1)的命令是安全的
- O(N)命令可以认为是危险的,使用时必须要注意
- 内存设置
- 32 位最大占用 3G
- 64 位默认没有上限
- maxmemory 10g
- 延迟
- 查看虚拟机命令执行延迟
./redis-cli --intrinsic-latency 100- 内核的 transparent_hugepage 参数
- 慢日志配置参数
slowlog-log-slower-thanslowlog-max-len
- 避免使用/触发 swap 分区
- 危险命令/主从同步/key淘汰/数据持久化等引发的延迟
- 查看虚拟机命令执行延迟
内存问题定位
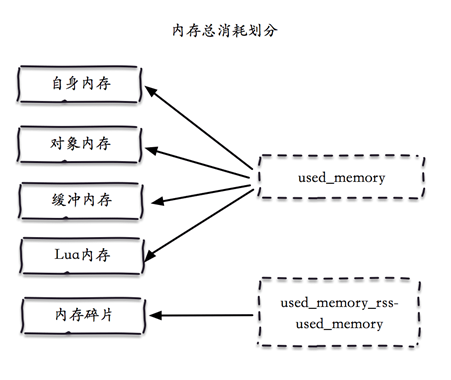
内存问题定位常用整理:
- info memory
- 计算公式
- used_memory = 自身内存+对象内存+缓冲内存+lua内存;
- used_rss = used_memory + 内存碎片
- 比较
used_memory和maxmemory - used_memory Redis 分配器分配的内存量,也就是实际存储数据的内存总量
- used_memory_human 以可读格式返回 Redis 使用的内存总量
- used_memory_rss 从操作系统的角度,Redis进程占用的总物理内存
- used_memory_dataset 数据集占用
- used_memory_dataset_perc 数据集占用百分比
- used_memory_peak 内存分配器分配的最大内存,代表used_memory的历史峰值
- used_memory_peak_human 以可读的格式显示内存消耗峰值
- used_memory_lua Lua 引擎所消耗的内存
- used_memory_overhead 缓冲区占用
- mem_fragmentation_ratio = used_memory_rss /used_memory比值,表示内存碎片率
- CONFIG SET activedefrag yes
- mem_allocatorRedis 所使用的内存分配器。默认: jemalloc
- 计算公式
- 查找 big key
- big key引发的问题
- 导致内存空间不平衡,超时阻塞
- 流量打满网卡影响其他系统
- 大量写入时会导致缓冲区占满导致无法处理请求,进而引发更多的请求/雪崩
- redis-cli -h 127.0.0.1 -p 7001 –-bigkeys
- big key引发的问题
- info clients 汇总展示 client list 详细定位 omem 大于0(命令可能阻塞主线程)
- 客户端缓冲区(超过 1G 时连接会被关闭)
- redis 使用缓冲区临时保存请求命令,并从缓冲区里获取命令。
- 普通客户端缓冲区(例如 monitor 命令)
- pubsub 客户端缓冲区